
Meta-knowledge enrichment of the GENIA Event Corpus
NOTE: Please observe the terms of the meta-knowledge corpus licence when downloading the corpus.
New! View the corpus online with the brat rapid annotation tool.
Background
The GENIA event corpus consists of 1000 MEDLINE abstracts that have been manually annotated with biomedical events. It was released in 2008 by the Tsujii laboratory at the University of Tokyo. The annotations provide classified, structured representations of relationships between biomedical terms, and as such, the corpus consitututes a valuable resource for the training of Information Extraction (IE) systems.
The original version of the GENIA event corpus concentrated on the following:
- Identification of the event trigger (the word or phrase around which the event is organised)
- Assignment of the event type
- Identification of the event participants, usually:
- THEME: the entity or event affected by the current event
- CAUSE: the entity or event that causes the current event to occur
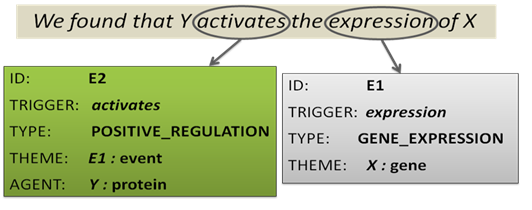 |
| Figure 1. Event Annotation Example |
The original GENIA event annotation was largely not concerned with how the textual context of an event can affect its interpretation. To illustrate this, consider the examples below. In each sentence, the event (triggered by the verb activate and its participants (narL gene product as the CAUSE and nitrate reductase operon as the THEME) are identical, although the way in which the events should be interpreted is different in each case.
1. It is known that the narL gene product activates the nitrate reductase operon
2. We examined whether the narL gene product activates the nitrate reductase operon
3. The narL gene product did not activate the nitrate reductase operon
4. These results suggest that the narL gene product is activated by the nitrate reductase operon
5. The narL gene product partially activated the nitrate reductase operon
6. Previous studies have shown that the narL gene product activates the nitrate reductase operon
In sentence 1), the word known tells us that the event is a generally accepted fact, while in 2), the interpretation is completely different. The word examined denotes that the event is under investigation, and hence the truth value of the event is unknown. The presence of the word not in sentence 3) shows that the event is negated, i.e. it did not happen. In sentence 4), the verb suggest, together with its subject adds further speculation regarding the truth of the event. The word partially in sentence 4) does not challenge the truth of the event, but rather conveys the information that the strength or intensity of the event is less than may be expected by default. Finally, the phrase previous studies in sentence 5) shows that the event is based on information available in previously published papers, rather than relating to new information from the current study.
Meta-knowledge annotation scheme
We have defined an annotation scheme that aims to enrich events in the GENIA event corpus (as well as other corpora annotated with biomedical events) with several types of information relating to their interpretation. This will then facilitate the training of more advanced IE systems that allow aspects of event intepretation to be specified as additional search criteria (e.g., retrieve only those events that describe well-known facts, or those that describe new experimental knowledge). The annotation scheme represents event interpretation by means of 5 separate dimensions of annotation, which are summarised in figure 2. Further details can be found in our annotation guidelines
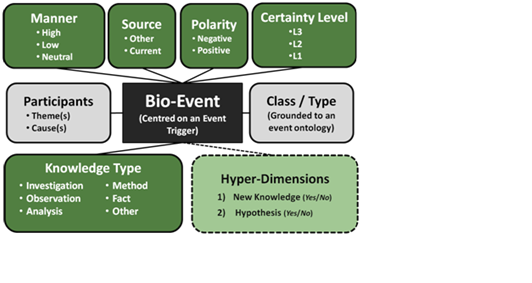 |
| Figure 2. Meta-knowledge annotation scheme |
Each annotation dimension consists of a fixed set of possible values. For each individual event, the annotation task consists of selecting an appropriate value from the possible set for each of the 5 annotation dimensions. In addition, any words or phases that are used to determine the different dimension values (such as those highlighted in sentences 1)- 5) above) are annotated as clue expressions.
The complete version of the GENIA corpus enriched with meta-knowledge annotation is available for download.
Automatic identification of meta-knowledge
We have carried out work on training systems to automatically recognise meta-knowledge, using the meta-knowledge corpus as training data. The efforts so far are as follows:- In Nawaz et al. (2012), we focus specifically on the automatic recognition of the Manner dimension using random forests, given pre-recognised/annotated events.
- In Miwa et al. (2012), we report on a extension to the EventMine event extraction system, which allows events to be automatically extracted, with meta-knowledge assigned to them
References
Thompson, P., Nawaz, R., McNaught, J. and Ananiadou, S. (2011). Enriching a biomedical event corpus with meta-knowledge annotation. BMC Bioinformatics, 12:393. (Highly Accessed)Nawaz, R., Thompson, P. and Ananiadou, S.. (2012). Identification of Manner in Bio-Events. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC 2012), pp. 3505-3510
Miwa, M., Thompson, P., McNaught, J., Kell, D.B and Ananiadou, S. (2012). Extracting semantically enriched events from biomedical literature. BMC Bioinformatics, 13:108 (Highly Accessed)
Meta-knowledge corpus licence
1. Copyright of abstracts
Any abstracts contained in this corpus are from PubMed(R), a database of the U.S. National Library of Medicine (NLM).
NLM data are produced by a U.S. Government agency and include works of the United States Government that are not protected by U.S. copyright law but may be protected by non-US copyright law, as well as abstracts originating from publications that may be protected by U.S. copyright law.
NLM assumes no responsibility or liability associated with use of copyrighted material, including transmitting, reproducing, redistributing, or making commercial use of the data. NLM does not provide legal advice regarding copyright, fair use, or other aspects of intellectual property rights. Persons contemplating any type of transmission or reproduction of copyrighted material such as abstracts are advised to consult legal counsel.
2. Copyright of Event Annotations
See the GENIA Project License for Annotated Corpora3. Copyright of Meta-Knowledge Annotations

The meta-knowledge annotations within the abstracts are the result of work carried out at the National Centre for Text Mining (NaCTeM), School of Computer Science, University of Manchester, UK. The annotations are copyrighted and licenced by NaCTeM under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
Please attribute the corpus by citing the following paper:
Thompson, P., Nawaz, R., McNaught, J. and Ananiadou, S. (2011). Enriching a biomedical event corpus with meta-knowledge annotation. BMC Bioinformatics, 12:393.
Featured News
- NaCTeM success at EMNLP 2025 - 7/7 papers accepted
- 1st Workshop on Misinformation Detection in the Era of LLMs - Presentation slides now available
- Prof. Ananiadou appointed Deputy Director of the Christabel Pankhurst Institute
- ELLIS Workshop on Misinformation Detection - Presentation slides now available
- Prof. Sophia Ananiadou accepted as an ELLIS fellow
- BioNLP 2025 and Shared Tasks accepted for co-location at ACL 2025
- Prof. Junichi Tsujii honoured as Person of Cultural Merit in Japan
![]() Featured News Feed
Featured News Feed
Other News & Events
- AI for Research: How Can AI Disrupt the Research Process?
- CL4Health @ NAACL 2025 - Extended submission deadline - 04/02/2025
- Invited talk at the 15th Marbach Castle Drug-Drug Interaction Workshop
- Participation in panel at Cyber Greece 2024 Conference, Athens
- Shared Task on Financial Misinformation Detection at FinNLP-FNP-LLMFinLegal
![]() Other News Feed
Other News Feed


![]()




