
Mining Biodiversity: Enriching Biodiversity Heritage with Text Mining and Social Media
 Mining Biodiversity is one of the projects that won in the third round of the transatlantic Digging Into Data Challenge, a competition aiming to promote the development of innovative computational techniques that can be applied to big data in the humanities and social sciences. Overall, 14 teams representing collaborations from Canada, US, UK and the Netherlands have been selected. Four of the selected projects come from the UK.
Mining Biodiversity is one of the projects that won in the third round of the transatlantic Digging Into Data Challenge, a competition aiming to promote the development of innovative computational techniques that can be applied to big data in the humanities and social sciences. Overall, 14 teams representing collaborations from Canada, US, UK and the Netherlands have been selected. Four of the selected projects come from the UK.
The project is an international collaboration between the National Centre for Text Mining (UK), Missouri Botanical Garden (US), Dalhousie University's Big Data Analytics Institute (Canada) and Ryerson University's Social Media Lab (Canada). NaCTeM was also a recipient of the 2011 Digging into Data call with the Integrated Social History Environment for Research (ISHER) project.
Summary
The Mining Biodiversity project aims to transform the Biodiversity Heritage Library (BHL) into a next-generation social digital library resource to facilitate the study and discussion (via social media integration) of legacy science documents on biodiversity by a worldwide community and to raise awareness of the changes in biodiversity over time in the general public. The project integrates novel text mining (TM) methods, visualisation, crowdsourcing and social media into the BHL. The resulting digital resource will provide fully interlinked and indexed access to the full content of BHL library documents, via semantically enhanced and interactive browsing and searching capabilities, allowing users to locate precisely the information of interest to them in an easy and efficient manner.
Project goals
By promoting the development of capabilities that will foster collaboration amongst researchers from the fields of History of Science, Environmental History, Environmental Studies, Library and Information Science and Social Media, the proposed project will make a significant impact on the above disciplines by:
- enriching a large-scale library, i.e., the BHL, via innovative application of text mining techniques to produce semantic metadata and a term inventory,
- providing improved access to biodiversity-related digital artifacts via an enhanced search engine and visualisation of results, and
- stimulating increased collaboration, interaction and sharing of information amongst BHL users via the social media environment.
Details
The project has five major components:
- Automatic correction of errors in text extracted automatically from legacy biodiversity literature via optical character recognition (OCR).
- Development of a crowdsourcing facility that will encourage users to annotate legacy texts with semantic metadata.
- Adaptation of text mining technologies to extract metadata (i.e., terminology, entities and significant events) automatically and to track terminology evolution over time. This will facilitate semantic search, allowing users to explore search results according to multiple information dimensions or facets.
- Interactive visualisation techniques will be used to help users to make sense of search results through the integration of next generation browsing capabilities, assisted by a semantic similarity network of important terms and entities.
- Design of a social media layer, serving as an environment for diverse users to interact and collaborate on science, public education, awareness and outreach.
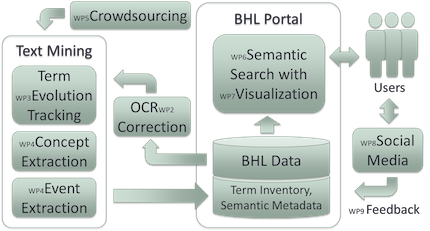 Architecture
Architecture
Project information
The project ran from March 2014 until September 2015, and was funded by AHRC, ESRC, Innovation.ca, Institute of Museum and Library Services, JISC and NEH.
Publications
Batista-Navarro, R., Hammock, J., Ulate, W. and Ananiadou, S. (2016). A Text Mining Framework for Accelerating the Semantic Curation of Literature. In: Proceedings of the 20th International Conference on Theory and Practice of Digital Libraries (TPDL 2016), pp. 459-462, Springer
Batista-Navarro, R., Soto, A., Ulate, W. and Ananiadou, S. (2016). Text Mining Workflows for Indexing Archives with Automatically Extracted Semantic Metadata. In: Proceedings of the 20th International Conference on Theory and Practice of Digital Libraries (TPDL 2016), pp. 471-473, Springer
Talks
A talk entitled Enriching the legacy literature with OCR corrections and text-mined semantic metadata at the Annual Conference of Biodiversity Information Standards (TDWG) 2014 in Jönköping, Sweden.
A talk entitled Unlocking knowledge in biodiversity legacy literature through automatic semantic metadata extraction at the Annual Conference of Biodiversity Information Standards (TDWG) 2015 in Nairobi, Kenya.
A tutorial entitled Text mining workflows for indexing archives with automatically extracted semantic metadata at the 20th International Conference on Theory and Practice of Digital Libraries in Hannover, Germany.
A talk entitled Expanding Access to Biodiversity Literature at the 48th Annual Meeting of the Council on Botanical and Horticultural Libraries in Cleveland, Ohio
Project Partners
Prof. Sophia Ananiadou, University of Manchester
William Ulate, Missouri Botanical Garden
Dr. Anatoliy Gruzd, Ryerson University
Project Team
University of Manchester: Prof. Sophia Ananiadou, Dr. Eva Maria Navarro Lopez, Dr. R. Tucker Gilman, Dr. Riza Batista-Navarro, Dr. Georgios Kontonatsios, Dr. Axel Soto
Missouri Botanical Garden: William Ulate, Trish Rose-Sandler
Dalhousie University: Prof. Evangelos Milios, Prof. Stan Matwin, Dr. Vlado Keselj, Dr. Stephen Brooks
Ryerson University: Dr. Anatoliy Gruzd
Futher information
- Contact us: Prof. Sophia Ananiadou.
Featured News
- 1st Workshop on Misinformation Detection in the Era of LLMs - Presentation slides now available
- Prof. Ananiadou appointed Deputy Director of the Christabel Pankhurst Institute
- ELLIS Workshop on Misinformation Detection - Presentation slides now available
- Prof. Sophia Ananiadou accepted as an ELLIS fellow
- BioNLP 2025 and Shared Tasks accepted for co-location at ACL 2025
- Prof. Junichi Tsujii honoured as Person of Cultural Merit in Japan
![]() Featured News Feed
Featured News Feed
Other News & Events
- AI for Research: How Can AI Disrupt the Research Process?
- CL4Health @ NAACL 2025 - Extended submission deadline - 04/02/2025
- Invited talk at the 15th Marbach Castle Drug-Drug Interaction Workshop
- Participation in panel at Cyber Greece 2024 Conference, Athens
- Shared Task on Financial Misinformation Detection at FinNLP-FNP-LLMFinLegal
![]() Other News Feed
Other News Feed


![]()




