
Health and Safety Executive (HSE)
Lloyds Register Foundation
Introduction
The Lloyds HSE project is under the umbrella of the £10 million Discovering Safety programme funded by Lloyd's Register Foundation. Central to the programme is the development of new technologies to analyse data and aggregate data from sources worldwide, the key output being new learning to help prevent future accidents occurring. This ambitious programme is a collaboration between the Health and Safety Executive (HSE) and the University of Manchester, delivered as part of the Thomas Ashton Institute. As part of the programme, we are using state of the art in text mining and natural language processing to extract health and safety insights from free-text sources.
Aims and Objectives
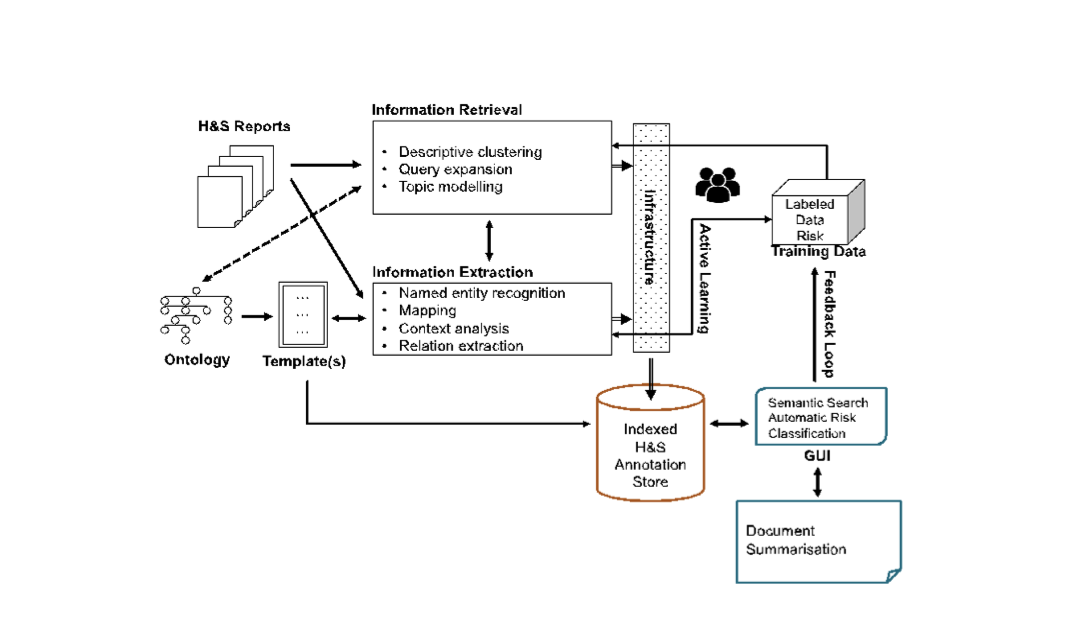
HSE's rich and varied archive of health and safety data, accrued year on year from its workplace inspection, incident investigation and enforcement activities, along with the incident information reported to HSE by its duty holders, provides a ready-made research dataset to support the creation of an ecosystem for automatically generating insights and support health and safety risk assessment. To achieve this aim, the objectives of this project are:
- to identify groups of thematically related documents and to generate informative labels to characterise the content of each topic using topic analysis and descriptive clustering;
- to customise and integrate text mining resources and tools to enrich health and safety data with semantic metadata (terms, named entities and relations) automatically extracted from free-text reports;
- to find and assess risk factors automatically using context classification;
- to implement and evaluate an interactive and faceted semantic search system to support discovery based on query expansion and mapping methods;
- to automatically summarise reports based on risks and other semantic information of relevance;
- to demonstrate the above methodologies using a specific case study.
Framework
-
Information retrieval
Going beyond keyword queries, we use a combination of machine learning and text mining to retrieve relevant information from health and safety incident or inspection reports. -
Information extraction
We use information extraction techniques to automatically extract specific entities referenced in textual data, e.g., people, plants and places relating to a workplace along with any reference to key properties, processes and underlying associations. The extracted information will be integrated with traditional root cause analysis exercises, or the routine use of operating experience classifications and taxonomies. Semantic annotations and information extraction tools will support knowledge discovery, search and other applications e.g. diagnostic tools, optimisation, predictive analysis, etc. We use APLenty, an annotation tool for creating high-quality sequence labelling datasets using active and proactive learning, for creating the labelled data. -
Risk assessment
Once free text has been effectively annotated, its content can then be used in more quantitative, inferential type statistical analyses. For example, historic inspection findings might be used to generate insights to help target future inspection efforts and scope. -
Semantic/cognitive applications
The conversion of knowledge to understanding requires comprehension, judgment and intellect, historically contingent on human input. Key cognitive application areas will include: a) semantic search to retrieve information from knowledge bases, b) classification to support risk assessment and recommender systems, c) document summarisation.
Prototype semantic search system
A prototype web-based system, providing semantically-enhanced search over a collection of workplace accident reports (RIDDORs), is now available at http://www.nactem.ac.uk/hse/.
A video demonstrating the functionality of the system is also available.
News
21st July 2021
The HSEarch semantic search system is the focus of a news article entitled Down in the data mine, something stirs... on ITTHub.net, which provides news, opinion and insight into innovation and technology in road-based transport. The article describes how the system enables health and safety managers, contractors and HSE inspectors to extract pertinent safety-critical concepts and associations without the labour of trawling through thousands of pages of text, and features quotes from interviews with NacTeM's director, Prof. Sophia Ananiadou, as well Tim Yates, data scientist at HSE.
25th July 2019
We achieved first place in the Computational Linguistics Scientific Document Summarization Shared Task (CL-SciSumm 2019) at the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France
Publications
Emrah Inan, Paul Thompson, Tim Yates,and Ananiadou, S. (2021). HSEarch: semantic search system for workplace accident reports. In Proceedings of the 43rd European Confererence on Information Retrieval (ECIR 2021)
Thy Thy Tran, Phong Le and Sophia Ananiadou. 2020. Revisiting Unsupervised Relation Extraction. In Proceedings of the 58th Annual Conference of the Association for Computational Linguistics (ACL 2020), pp. 7498-7505.
Paul Thompson, Tim Yates, Emrah Inan and Sophia Ananiadou. 2020. Semantic Annotation for Improved Safety in Construction Work. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC 2020), pp. 1983 - 1992.
Chrysoula Zerva, Minh-Quoc Nghiem, Nhung T.H. Nguyen, and Sophia Ananiadou. 2020. Cited text span identification for scientific summarisation using pre-trained encoders. Scientometrics (2020). https://doi.org/10.1007/s11192-020-03455-z.
Chrysoula Zerva, Minh-Quoc Nghiem, Nhung T.H. Nguyen, and Sophia Ananiadou, 2019. NaCTeM-UoM @ CL-SciSumm 2019. In Proceedings of the 4th Joint Workshop on Bibliometric-enhanced Information Retrieval and Natural Language Processing for Digital Libraries (BIRNDL 2019) at SIGIR
Project Team
Principal Investigator: Prof. Sophia Ananiadou
Researchers: Dr. Emrah Inan, Dr. Minh-Quoc Nghiem, Dr. Chrysoula Zerva, Dr. Fenia Christopoulou, Dr. Phong Le

![]()
Featured News
- AI for Research: How Can AI Disrupt the Research Process?
- ELLIS Workshop on Misinformation Detection - Presentation slides now available
- 1st Workshop on Misinformation Detection in the Era of LLMs (MisD)- 23rd June 2025
- Prof. Sophia Ananiadou accepted as an ELLIS fellow
- Invited talk at the 15th Marbach Castle Drug-Drug Interaction Workshop
- BioNLP 2025 and Shared Tasks accepted for co-location at ACL 2025
- Prof. Junichi Tsujii honoured as Person of Cultural Merit in Japan
- Participation in panel at Cyber Greece 2024 Conference, Athens
- New Named Entity Corpus for Occupational Substance Exposure Assessment
![]() Featured News Feed
Featured News Feed
Other News & Events
- CL4Health @ NAACL 2025 - Extended submission deadline - 04/02/2025
- Shared Task on Financial Misinformation Detection at FinNLP-FNP-LLMFinLegal
- FinNLP-FNP-LLMFinLegal @ COLING-2025 - Call for papers
- Keynote talk at Manchester Law and Technology Conference
- Keynote talk at ACM Summer School on Data Science, Athens
![]() Other News Feed
Other News Feed


![]()




