 — Online demo is available!
— Online demo is available!
MEDIE is an intelligent search engine to retrieve biomedical
correlations from MEDLINE. You can find abstracts/sentences in MEDLINE
by specifying semantics of correlations; for example, "What
activates p53" and "What
causes colon cancer".
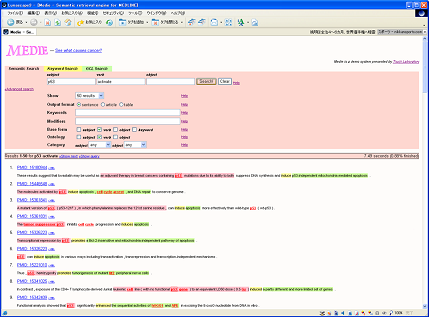
Currently, more than 18,000,000 MEDLINE articles are indexed.
This system is an outcome of recent developments of natural language processing technologies, such as HPSG parsing and structural text search. Our research group has been engaged in the development of fundamental technologies and software for natural language processing, and this system demonstrates a possibility of these technologies for real-world applications.
An overview of the technologies employed in this system is given below.
We developed a wide-coverage HPSG parser for English. This parser, Enju, outputs predicate argument structures as well as phrase structures. Although this parser has been trained with newswire articles, it can compute accurate analyses of biomedical texts owing to our method for domain adaptation.
Efficiency is also a great concern about natural language parsing. Our extensive studies on parsing efficiency enabled us to analyze real-world sentences in around one second per sentence. The technologies include an efficient engine for typed feature logic, quick check, and iterative beam search.
For details, see Enju Home Page.
Despite state-of-the-art parsing technologies listed above, natural language parsing is still a heavy task. Parsing of all sentences in MEDLINE requires considerable computational cost. We used two geographically separated computer clusters having 170 nodes (340 Xeon CPUs). These two clusters are separately administered and not dedicated to us. No particular environment for load sharing across them are installed.
To effectively utilize such an environment, the GXP parallel and distributed shell was used to connect these two clusters and distribute load among them without any help from the administrators. Our experiences indicate GXP is very appropriate for scaling compute-intensive NLP tasks, because we can easily utilize multiple, separately administered compute resources without extensive setup by the administrators.
In natural language processing research, a number of methods have been investigated for the recognition of biomedical technical terms. Our research group has also developed machine learning methods for the automatic identification of biomedical terms. Our group has also been taking the initivative of the development of training/test data for this task.
We applied a dictionary-based method for the automatic and exhaustive annotation of technical terms in MEDLINE. This method not only identifies technical terms but also makes links to identifiers in ontologies. Ontological identifiers allow us to retrieve technical terms described in various notations.
For details, see GENIA Home Page.
To retrieve sentences or abstracts by specifying structures of tag-annotated documents, we adopted a framework of region algebra. Region algebra represents document structures by specifying containment and ordering relations of regions, such as a fragment of text from a beginning tag to the corresponding end tag.
We developed an algorithm to search regions matching a query of region algebra. This algorithm retrieves regions efficiently by skipping regions not concerning to the query. This algorithm can treat nested regions, which are common in phrase structures such as a noun phrase containing other noun phrases. We also incorporated variables into region algebra in order to specify re-entrant structures.
 Use this banner to link this page.
Use this banner to link this page.